1:创新点:如何用大数据分析学生行为来进行个性化推荐的
 一种针对学生学习行为的大数据分析与推荐系统,该系统包括:
一种针对学生学习行为的大数据分析与推荐系统,该系统包括:
内容传送模块、
预测模块、
自适应显示模块、
自适应模块、
干预模块以及学习者数据库模块;
其中,所述内容传送模块负责将学习者生成的学习行为数据标记上时间戳,并传递给所述学习者数据库模块;所述学习者数据库模块负责存储预先定义的数据参数结构;所述预测模块负责将所采集数据根据不同的分析目的,调用不同的分析工具及数学模型对相关数据进行分析,并传递分析结果至所述自适应显示模块;所述自适应显示模块根据所述预测模块中数据挖掘及分析的结果,通过所述内容传送模块为学习者推荐合适的学习指导和学习策略;所述干预模块负责根据分析结果对系统进行人为干预。
进一步地,所述内容传送模块主要负责管理、维护、传递个性化的学习内容与评价给学习者,以支持学习者的各种学习行为。
进一步地,所述预测模块整合了系统外部学习者信息系统中的数据以及系统内部学习者学习的行为数据,通过对数据的处理和分析,对学习者未来的学习行为和结果进行预测。
进一步地,所述自适应显示模块主要负责将所述预测模块中的处理结果以可视化的方式显示给各类使用者。
进一步地,所述自适应模块是整个系统的重点,其采用的技术主要是基于大数据挖掘和分析的学习资源推送机制。
进一步地,所述干预模块可以识别学习者的行为模式,是对学习者学习产生影响的介入手段。
进一步地,所述学习者数据库模块主要存储了大量学习者在本系统中的被标记时间戳的输入数据及学习行为数据。
通过收集教育过程中的学习行为数据,利用大数据的学习分析技术,有针对性地推送学习内容,及时反馈学习者的学习效果,并推荐下一步的学习策略,实现了因材施教和培养学生自主学习能力的效果。
2:应用价值:我们在广理工或者其他平台推广应用了,有实际应用价值。
广东理工职业学院,广东开放大学
3:推荐算法,用了哪些算法。
推荐算法:
基于人口学的推荐、基于内容的推荐、基于用户的协同过滤推荐、基于项目的协同过滤推荐、基于模型的协同过滤推荐、基于关联规则的推荐
fm(Factorization Machines 分解机算法)
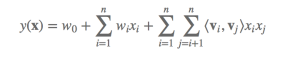
LR(logistic regression 逻辑回归)
逻辑回归本质上是线性回归,只是在特征到结果的映射中加入了一层逻辑函数g(z),即先把特征线性求和,然后使用函数g(z)作为假设函数来预测。g(z)可以将连续值映射到0 和1。g(z)为sigmoid function.
embedding

协同过滤的itemCF,userCF区别适用场景
Item CF(Item Collaboration Filter基于商品的协同过滤算法) 和 User CF(User Collaboration Filter 基于用户的协同过滤算法)两个方法都能很好的给出推荐,并可以达到不错的效果。但是他们之间还是有不同之处的,而且适用性也有区别。下面进行一下对比.
原理
userCF是用户相似度矩阵(可通过余弦相似度)评分矩阵(用户对商品的评分矩阵)
ItemCF是商品相似度矩阵评分矩阵转置计算复杂度:
在非社交网站,如购物网站中,用户数量可能远远大于商品数量,ItemCF复杂度比UserCF复杂度低; 在社交网站中,UserItem复杂度比ItemCF复杂度低.适用场景:
在非社交网站,如购物网站中,ItermCF更适用,在社交网站中,UserItem更适用.
在非社交网络的网站中,内容内在的联系是很重要的推荐原则,它比基于相似用户的推荐原则更加有效。
比如在购书网站上,当你看一本书的时候,推荐引擎会给你推荐相关的书籍,这个推荐的重要性远远超过了网站首页对该用户的综合推荐。可以看到,在这种情况下,Item CF 的推荐成为了引导用户浏览的重要手段。同时 Item CF 便于为推荐做出解释,在一个非社交网络的网站中,给某个用户推荐一本书,同时给出的解释是某某和你有相似兴趣的人也看了这本书,这很难让用户信服,因为用户可能根本不认识那个人;但如果解释说是因为这本书和你以前看的某本书相似,用户可能就觉得合理而采纳了此推荐。
相反的,在现今很流行的社交网络站点中,User CF 是一个更不错的选择,User CF 加上社会网络信息,可以增加用户对推荐解释的信服程度。
ItemCF、UserCF参考链接
推荐系统的大概步骤,解决冷启动
步骤:1)收集用户的所有信息。使用大数据计算平台对收集的信息进行处理,的到用户偏好数据。
将偏好数据导入喜好类型计算算法中进行预算计算,得到预算结果。
将推荐的结果导入数据库(redis、hbase)。
发开一个推荐引擎,对外开放接口,输出推荐结果。
解决冷启动的方案:
1)提供非个性化的推荐
最简单的例子就是提供热门排行榜,可以给用户推荐热门排行榜,等到用户数据收集到一定的时候,再切换为个性化推荐。例如Netflix的研究也表明新用户在冷启动阶段确实是更倾向于热门排行榜的,老用户会更加需要长尾推荐
2)利用用户注册信息
用户的注册信息主要分为3种:(1)获取用户的注册信息;(2)根据用户的注册信息对用户分类;(3)给用户推荐他所属分类中用户喜欢的物品。
3)选择合适的物品启动用户的兴趣
用户在登录时对一些物品进行反馈,收集用户对这些物品的兴趣信息,然后给用户推荐那些和这些物品相似的物品。一般来说,能够用来启动用户兴趣的物品需要具有以下特点:
比较热门,如果要让用户对物品进行反馈,前提是用户得知道这是什么东西;
具有代表性和区分性,启动用户兴趣的物品不能是大众化或老少咸宜的,因为这样的物品对用户的兴趣没有区分性;
启动物品集合需要有多样性,在冷启动时,我们不知道用户的兴趣,而用户兴趣的可能性非常多,为了匹配多样的兴趣,我们需要提供具有很高覆盖率的启动物品集合,这些物品能覆盖几乎所有主流的用户兴趣
4)利用物品的内容信息
用来解决物品的冷启动问题,即如何将新加入的物品推荐给对它感兴趣的用户。物品冷启动问题在新闻网站等时效性很强的网站中非常重要,因为这些网站时时刻刻都有新物品加入,而且每个物品必须能够再第一时间展现给用户,否则经过一段时间后,物品的价值就大大降低了。
5)采用专家标注
很多系统在建立的时候,既没有用户的行为数据,也没有充足的物品内容信息来计算物品相似度。这种情况下,很多系统都利用专家进行标注。
6)利用用户在其他地方已经沉淀的数据进行冷启动
以QQ音乐举例:QQ音乐的猜你喜欢电台想要去猜测第一次使用QQ音乐的用户的口味偏好,一大优势是可以利用其它腾讯平台的数据,比如在QQ空间关注了谁,在腾讯微博关注了谁,更进一步,比如在腾讯视频刚刚看了一部动漫,那么如果QQ音乐推荐了这部动漫里的歌曲,用户会觉得很人性化。这就是利用用户在其它平台已有的数据。
再比如今日头条:它是在用户通过新浪微博等社交网站登录之后,获取用户的关注列表,并且爬取用户最近参与互动的feed(转发/评论等),对其进行语义分析,从而获取用户的偏好。
所以这种方法的前提是,引导用户通过社交网络账号登录,这样一方面可以降低注册成本提高转化率;另一方面可以获取用户的社交网络信息,解决冷启动问题。
7)利用用户的手机等兴趣偏好进行冷启动
Android手机开放的比较高,所以在安装自己的app时,就可以顺路了解下手机上还安装了什么其他的app。比如一个用户安装了美丽说、蘑菇街、辣妈帮、大姨妈等应用,就可以判定这是女性了,更进一步还可以判定是备孕还是少女。目前读取用户安装的应用这部分功能除了app应用商店之外,一些新闻类、视频类的应用也在做,对于解决冷启动问题有很好的帮助。



